把下面图片中的衣服,换到视频里的模特身上,你需要分几步走?

爱奇艺AI团队的答案是“一键换装”。
近日,国际AI顶级会议CVPR 2022公布了最新论文入选结果,爱奇艺AI团队的论文《ClothFormer: Taming Video Virtual Try-on in All Module》以Oral Presentation(口头报告论文)入选。论文研究的目标就是通过图像生成模型,把图片里的衣服,穿到视频中的人物身上。
CVPR(Computer Vision and Pattern Recognition)由IEEE主办,是计算机视觉领域的三大顶会(CVPR、ICCV、ECCV)之一。CVPR代表着AI学术领域的世界前沿水平。今年最终有2067篇论文被接收,接收率约为25%,Oral接收率更是不到5%。
爱奇艺AI团队的这篇论文提出了ClothFormer算法,并提出了业内首个基于真实场景的视频虚拟试穿数据集iQIYI-VVT,不仅能够更真实、自然地完成“虚拟换装”,也为业内深入研究该技术提供了丰富的数据支持。
有了爱奇艺这项技术,观众足不出户试穿影视剧同款、全世界潮流服饰的愿望指日可待。
虚拟换装≠软件修图
把图片里的衣服换到人身上,这项操作似乎和软件修图类似,实际上两者相差甚远。
假如给一支时长1分钟视频里的人换装,即使每秒只有25帧,也需要修改1500张图片,若是人物动作复杂、遮挡物多的视频,全部修改完也不一定能流畅播放。
这与“视频虚拟换装”的三大关键点有关:一是精准地把款式衣服变形,使其贴合模特动作,二是把衣服“穿”到模特身上,三是使生成的视频看上去够流畅。每个关键环节都存在众多难点,比如衣服变形不够精准,视频里的人物被遮挡或动作复杂,生成的视频不稳定,加上现有真实场景的数据集不足,很难准确理解复杂场景……这些问题都导致衣服无法“穿”到人身上。
为了解决“虚拟换装”面临的技术问题,爱奇艺AI团队提出ClothFormer算法,该算法重新对视频虚拟试穿框架进行了创新,有效改善了遮挡、视频稳定性等问题,降低了复杂姿态和复杂场景的挑战,换装后的视频也更加自然。(了解ClothFormer算法详情可访问:https://cloth-former.github.io/)
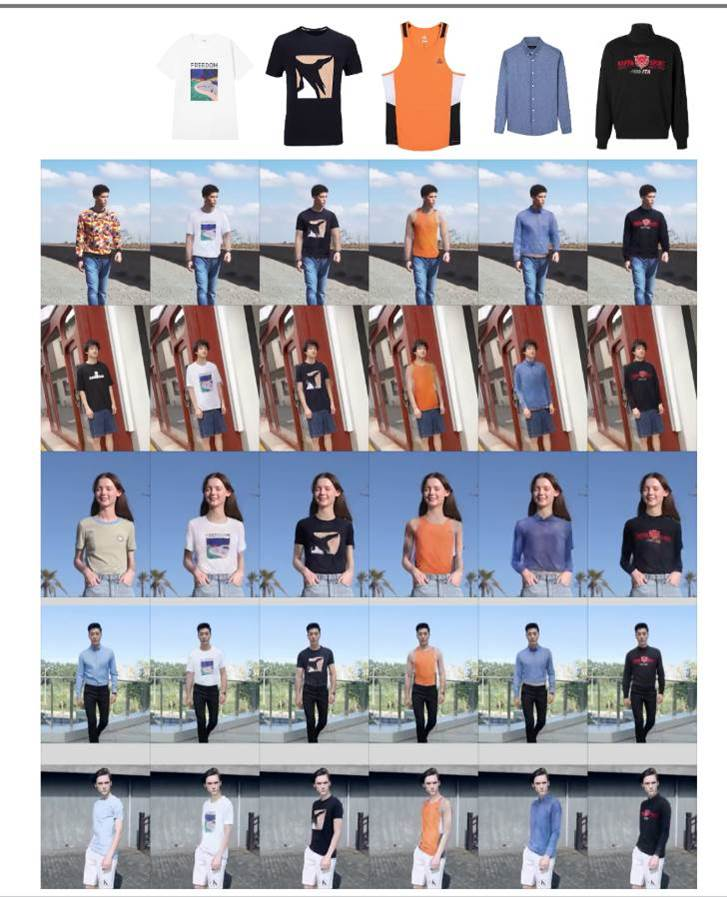
ClothFormer算法让“虚拟换装”走进真实场景
未来,在爱奇艺拍摄短视频,用户任意拿一张衣服的照片,或者影视剧剧照,就能给自己一键换装,真正实现“穿衣自由”。“虚拟换装”还可以用在虚拟制作中,比如拍摄结束后演员需要更换服装,通过虚拟换装技术给自动给演员更换,可以节省重新置景、拍摄的时间和成本。
近年来,“虚拟换装”成为热门研究领域,在CVPR等众多计算机视觉顶会中,越来越多的相关文章被收录。随着技术的进步,研究者们逐渐从小尺寸图片演变到高清图片以及视频的虚拟试穿,但大多仍限定在特定场景中,背景、姿态都比较简单,在真实场景上难以真正应用起来。ClothFormer算法则让“虚拟换装”进一步从实验走向真实场景。













